Moonbeam: A MIDI Foundation Model Using both Absolute and Relative Music Attributes
Authors: Zixun(Nicolas) Guo and Simon Dixon
Paper Code Release Model Release
Correspondence to: zixun.guo@qmul.ac.uk
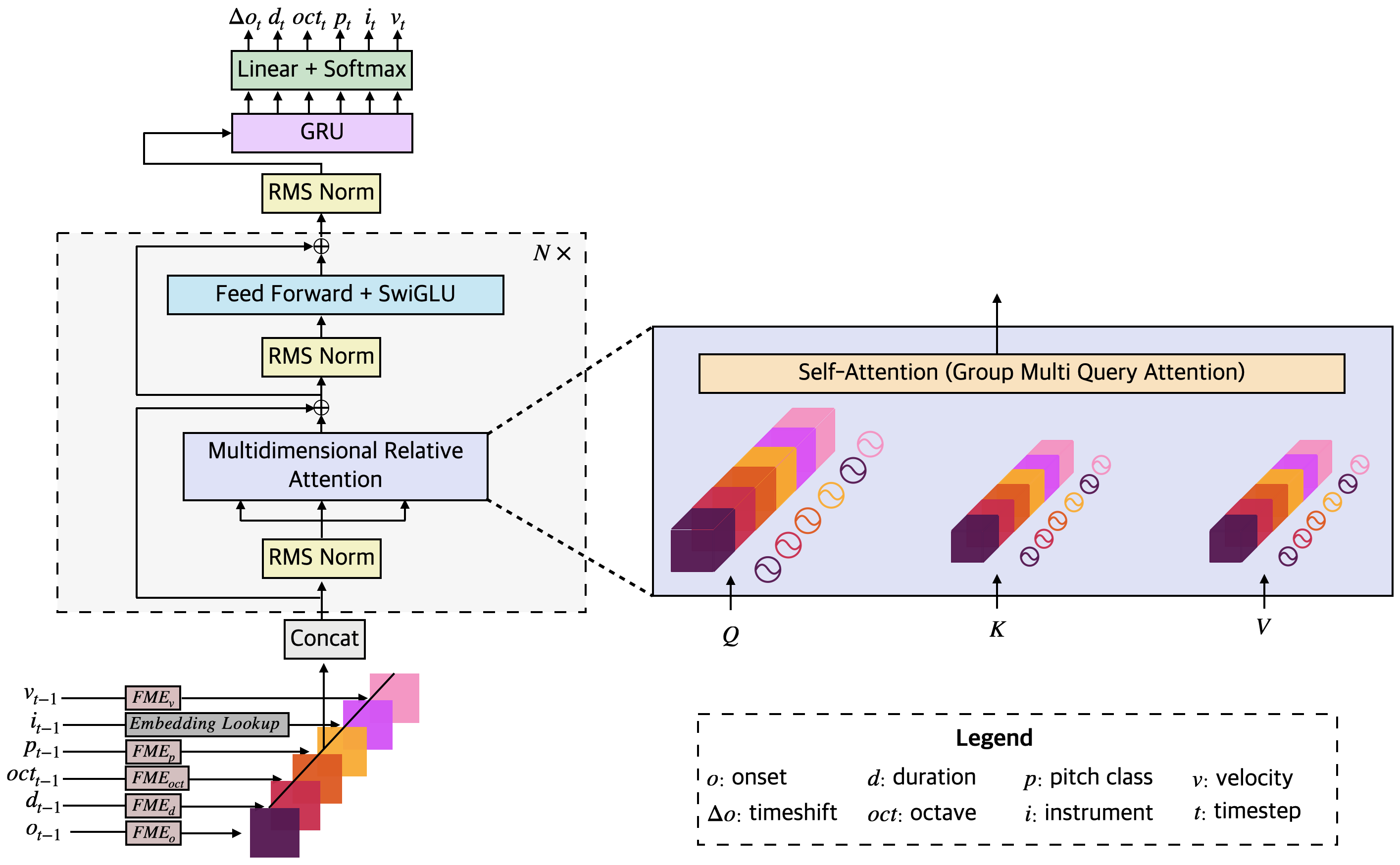
Pretrained Model Summary
Moonbeam is a transformer-based foundation model for symbolic music, pretrained on a large and diverse collection of MIDI data totaling 81.6K and 18 billion tokens. Unlike most existing transformer-based models for symbolic music, Moonbeam incorporates music-domain inductive biases by capturing both absolute and relative musical attributes through the introduction of a novel domain-knowledge-inspired tokenization method and a novel attention mechanism.
Downstream Task: Unconditional Prompt Continuation
Leveraging Moonbeam's generative capability, we finetuned Moonbeam using the following datasets: ATEPP (Classical Piano), GAPS (Classical Guitar) and Pijama (Jazz Piano). The resulting model is able to generate MIDI unconditionally, following an input prompt. The following MIDI samples are cherry-picked and synthesized using heavyocity.
| Fine-tuning Dataset | Prompt (Audio synthesized from MIDI) | Generation (Audio synthesized from MIDI) |
|---|---|---|
| ATEPP | ||
| ATEPP | ||
| ATEPP | ||
| GAPS | ||
| GAPS | ||
| GAPS | ||
| Pijama |
Downstream Task: Conditional Music Generation and Music Infilling
Conditional music generation is a task in which a model learns to compose music based on specified input conditions. One sub-task within this broader definition is music infilling, where the model learns to generate the missing parts or "fills", given an incomplete musical composition.
Moonbeam can be finetuned as a conditional music generator and has music infilling capabilities. We finetuned our model on the CoMMU dataset using the finetuning architecture proposed in the paper. The finetuned model could generate music based on chord and metadata controls.
Below we show 50 samples generated from our model and a transformer baseline with REMI-like tokenizer proposed in the CoMMU paper. For reference, we also provide the music composed by professional composers using the same condition. The samples below are randomly sampled without cherry-picking.
- Chord Controls
- Generated music based on the chord and metadata controls
Downstream Task: Symbolic Music Understanding
Moonbeam can also be finetuned for music representation learning and we show this by finetuning Moonbeam on three music understanding tasks, including player, composer and emotion classification, using four datasets. In most cases, our model outperforms other large-scale pretrained music models in terms of accuracy and F1 score.
| Dataset | Pijama30 | Pianist8 | Emopia | GPM30 | ||||
|---|---|---|---|---|---|---|---|---|
| Acc | F1 Macro | Acc | F1 Macro | Acc | F1 Macro | Acc | F1 Macro | |
| Clamp 2 | 0.44 | 0.219 | 0.892 | 0.891 | 0.659 | 0.652 | 0.644 | 0.549 |
| M3 | 0.262 | 0.077 | 0.784 | 0.786 | 0.715 | 0.688 | 0.385 | 0.16 |
| MusicBert | 0.55 | 0.452 | 0.811 | 0.806 | 0.682 | 0.674 | 0.63 | 0.575 |
| Moonbeam (S) | 0.649 | 0.596 | 0.811 | 0.804 | 0.636 | 0.623 | 0.541 | 0.470 |
| Moonbeam (M) | 0.679 | 0.638 | 0.946 | 0.947 | 0.693 | 0.682 | 0.648 | 0.635 |
Releasing Moonbeam
The paper, code, and pretrained weights are released under the Apache License, Version 2.0.
- Paper: the paper describing the domain-knowledge-inspired tokenization method, attention that captures both absolute and relative music attributes, finetuning architecture for music classification, and finetuneing architecture for conditional music generation and music infilling.
- Code: code related to Moonbeam, including instructions for finetuning and the data preprocessing pipeline.
- Model Weights: the pretrained and finetuned model weights.
Fun Fact: Where Does the Name "Moonbeam" Come From?
The first author was traveling in Chiang Mai, Thailand, while searching for a name for his model. He was listening to "Polka Dots and Moonbeams", a jazz standard performed by Chet Atkins and Lenny Breau. Inspired, he then decided to name the model "Moonbeam".
Bibtex
@article{guo2025moonbeam,
title={Moonbeam: A MIDI Foundation Model Using both
Absolute and Relative Music Attributes},
author={Guo, Zixun and Dixon, Simon},
journal={arXiv preprint arXiv:2505.08620},
year={2025}
}